The human face plays a central role in social communication, necessitating the use of performant computer vision tools for human-centered applications. We propose Face-LLaVA, a multimodal large language model for face-centered, in-context learning, including facial expression and attribute recognition. Additionally, Face-LLaVA is able to generate natural language descriptions that can be used for reasoning. Leveraging existing visual databases, we first developed FaceInstruct-1M, a face-centered database for instruction tuning MLLMs for face processing. We then developed a novel face-specific visual encoder powered by Face-Region Guided Cross-Attention that integrates face geometry with local visual features. We evaluated the proposed method across nine different datasets and five different face processing tasks, including facial expression recognition, action unit detection, facial attribute detection, age estimation and deepfake detection. Face-LLaVA achieves superior results compared to existing open-source MLLMs and competitive performance compared to commercial solutions. Our model output also receives a higher reasoning rating by GPT under a zero-shot setting across all the tasks.
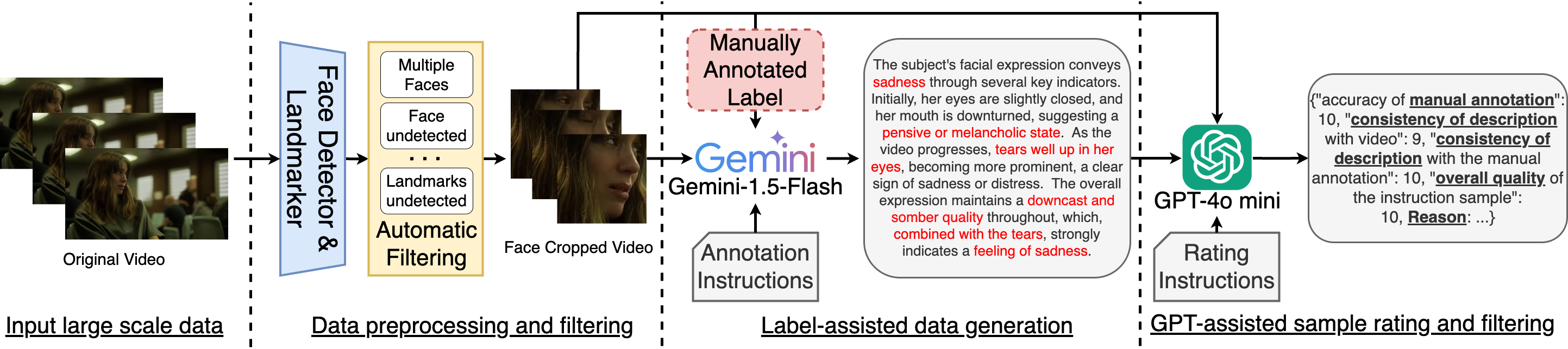
Overview of the data annotation pipeline used to construct FaceInstruct-1M dataset. We leverage existing face-analysis datasets and their annotations and prompt Gemini-1.5 flash to convert the annotations into natural language with reasoning. To ensure data quality, we rate the generated samples from GPT-4o-mini.
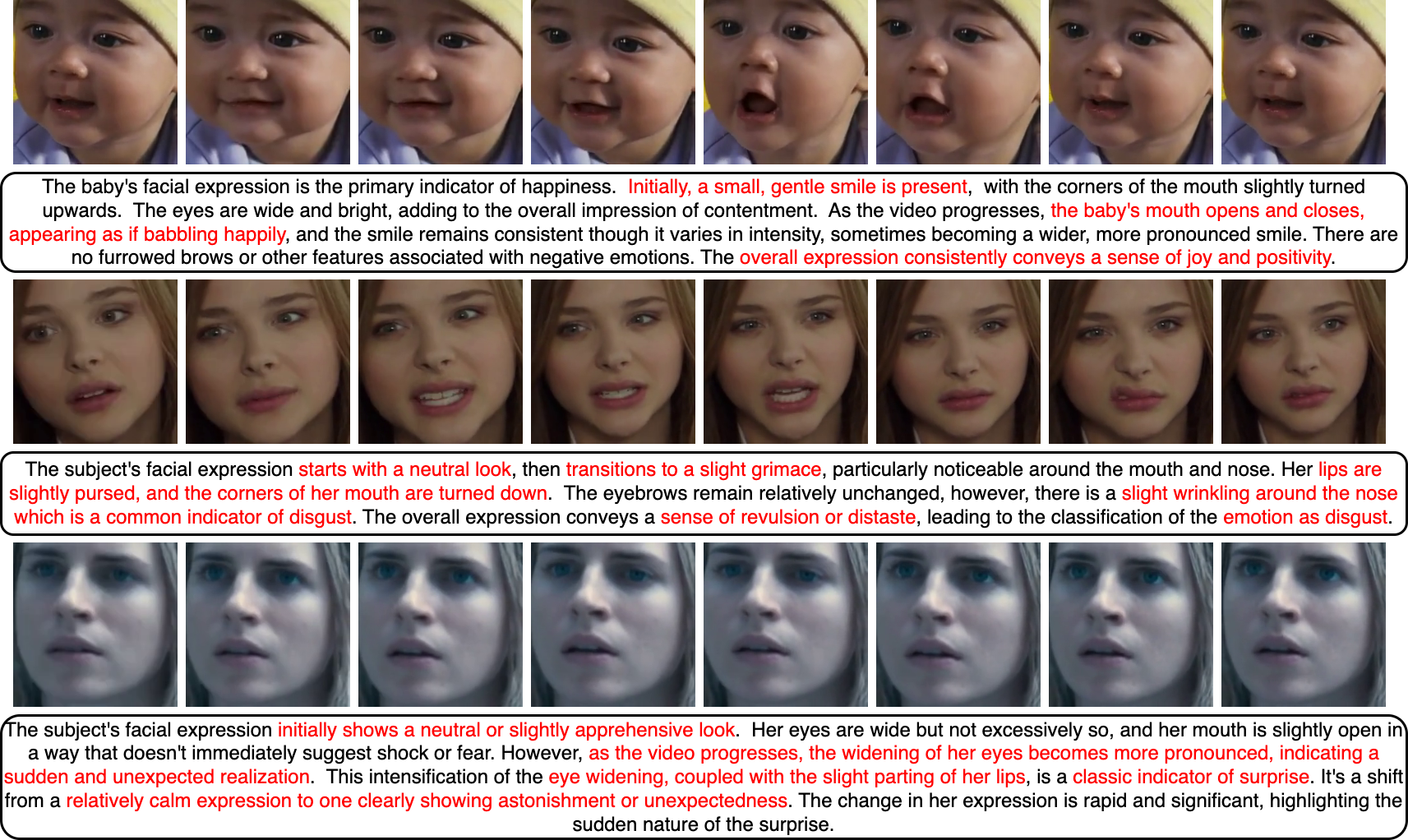

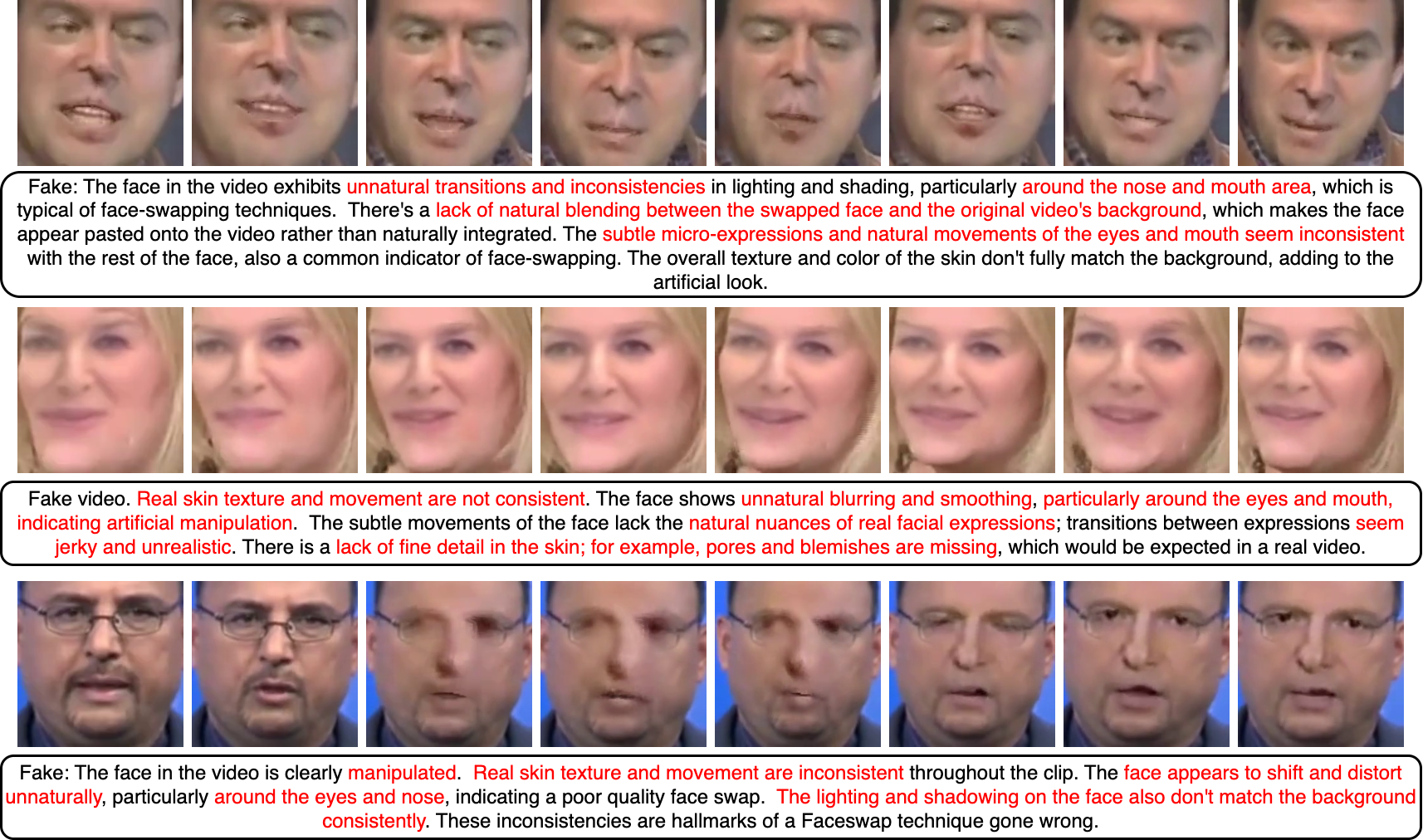

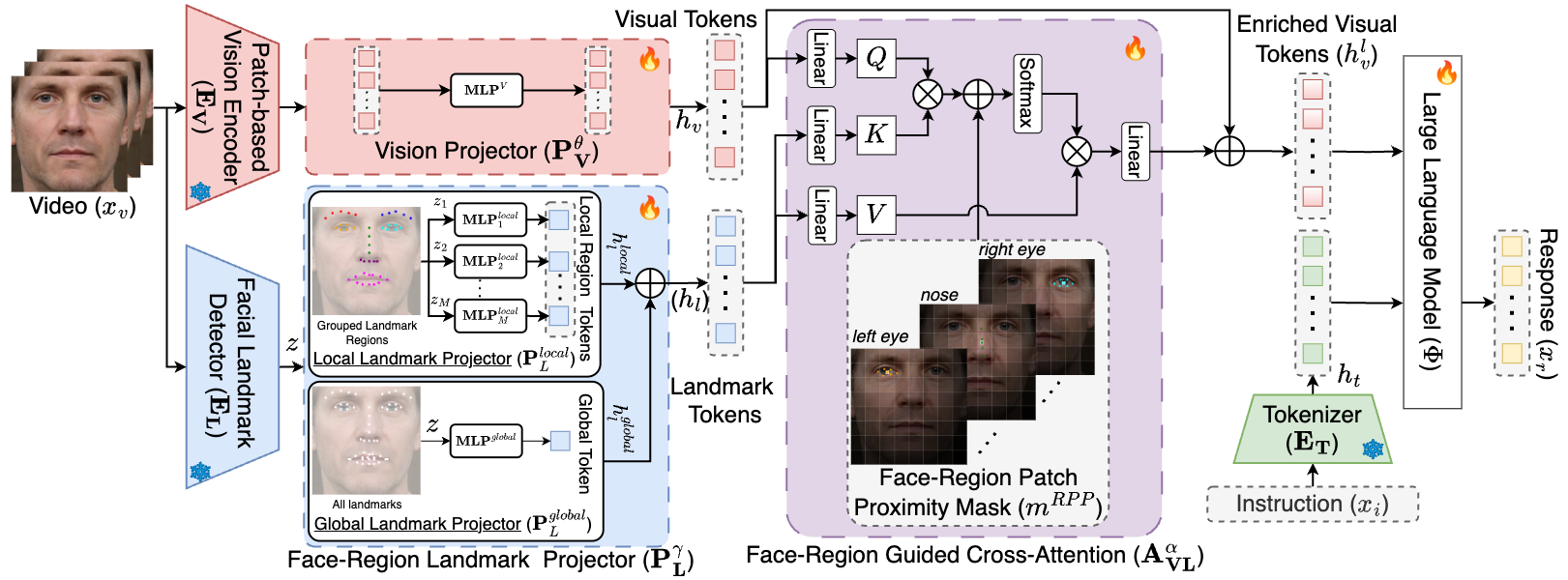
Overview of the proposed Face-LLaVA Architecture. We use a pretrained face expert model, i.e. a landmark detection model to extract landmarks from the visual input. We leverage our novel face-region landmark projector (FRLP) module to obtain landmark tokens which capture the face landmark information. To enrich the visual tokens, face-region guided cross attention is performed between visual tokens and landmark tokens guided by the face-region patch proximity mask.




@misc{chaubey2025facellava,
title={Face-LLaVA: Facial Expression and Attribute Understanding through Instruction Tuning},
author={Ashutosh Chaubey and Xulang Guan and Mohammad Soleymani},
year={2025},
eprint={2504.07198},
archivePrefix={arXiv},
primaryClass={cs.CV}
}Research was sponsored by the Army Research Office and was accomplished under Cooperative Agreement Number W911NF-25-2-0040. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein
